mirror of
https://github.com/oobabooga/text-generation-webui.git
synced 2024-12-24 13:28:59 +01:00
Merge branch 'main' of github.com:oobabooga/text-generation-webui
This commit is contained in:
commit
10e939c9b4
@ -125,7 +125,7 @@ cp .env.example .env
|
|||||||
docker compose up --build
|
docker compose up --build
|
||||||
```
|
```
|
||||||
|
|
||||||
Make sure to edit `.env.example` and set the appropriate CUDA version for your GPU.
|
Make sure to edit `.env.example` and set the appropriate CUDA version for your GPU, which can be found on [developer.nvidia.com](https://developer.nvidia.com/cuda-gpus).
|
||||||
|
|
||||||
You need to have docker compose v2.17 or higher installed in your system. For installation instructions, see [Docker compose installation](https://github.com/oobabooga/text-generation-webui/wiki/Docker-compose-installation).
|
You need to have docker compose v2.17 or higher installed in your system. For installation instructions, see [Docker compose installation](https://github.com/oobabooga/text-generation-webui/wiki/Docker-compose-installation).
|
||||||
|
|
||||||
|
|||||||
@ -1,38 +1,50 @@
|
|||||||
## Description:
|
## Description:
|
||||||
TL;DR: Lets the bot answer you with a picture!
|
TL;DR: Lets the bot answer you with a picture!
|
||||||
|
|
||||||
Stable Diffusion API pictures for TextGen, v.1.1.0
|
Stable Diffusion API pictures for TextGen, v.1.1.1
|
||||||
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
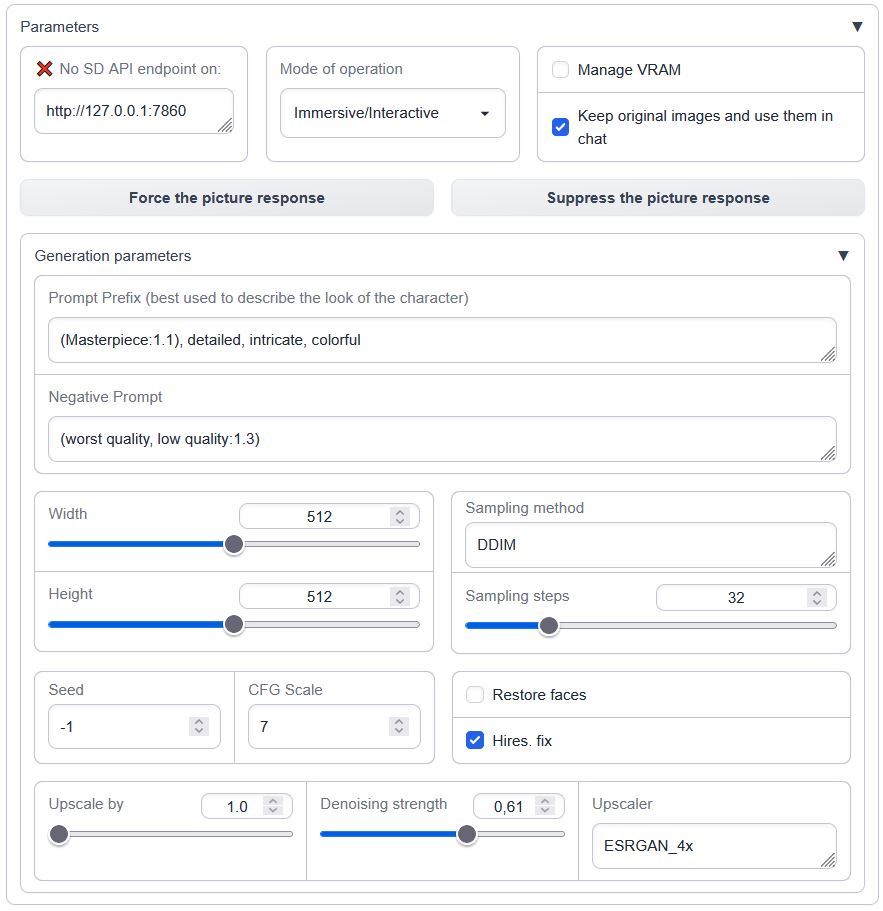
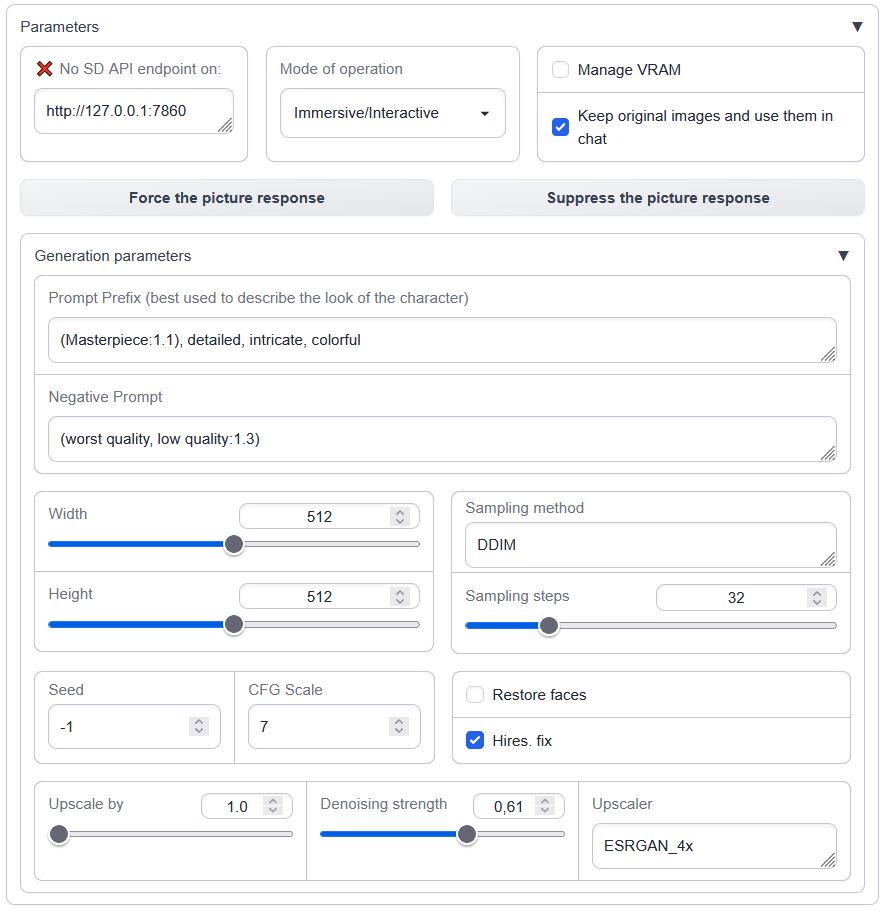
<summary>Interface overview</summary>
|
<summary>Interface overview</summary>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures` (it's not really required, but completes the picture, *pun intended*).
|
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures`
|
||||||
|
(it's not really required, but completes the picture, *pun intended*).
|
||||||
|
|
||||||
The image generation is triggered either:
|
|
||||||
|
## History
|
||||||
|
|
||||||
|
Consider the version included with [oobabooga's repository](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/sd_api_pictures) to be STABLE, experimental developments and untested features are pushed in [Brawlence/SD_api_pics](https://github.com/Brawlence/SD_api_pics)
|
||||||
|
|
||||||
|
Lastest change:
|
||||||
|
1.1.0 → 1.1.1 Fixed not having Auto1111's metadata in received images
|
||||||
|
|
||||||
|
## Details
|
||||||
|
|
||||||
|
The image generation is triggered:
|
||||||
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
||||||
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
||||||
- always on in Picturebook/Adventure mode (if not currently suppressed by 'Suppress the picture response')
|
- always on in `Picturebook/Adventure` mode (if not currently suppressed by 'Suppress the picture response')
|
||||||
|
|
||||||
## Prerequisites
|
## Prerequisites
|
||||||
|
|
||||||
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
||||||
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
||||||
|
|
||||||
## Features:
|
## Features overview
|
||||||
- API detection (press enter in the API box)
|
- Connection to API check (press enter in the address box)
|
||||||
- VRAM management (model shuffling)
|
- [VRAM management (model shuffling)](https://github.com/Brawlence/SD_api_pics/wiki/VRAM-management-feature)
|
||||||
- Three different operation modes (manual, interactive, always-on)
|
- [Three different operation modes](https://github.com/Brawlence/SD_api_pics/wiki/Modes-of-operation) (manual, interactive, always-on)
|
||||||
- persistent settings via settings.json
|
- User-defined persistent settings via settings.json
|
||||||
|
|
||||||
The model input is modified only in the interactive mode; other two are unaffected. The output pic description is presented differently for Picture-book / Adventure mode.
|
### Connection check
|
||||||
|
|
||||||
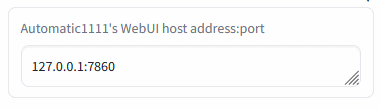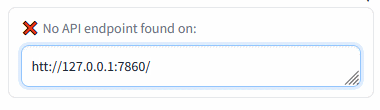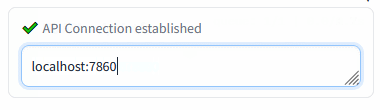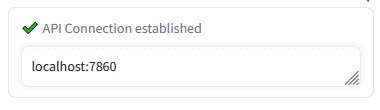
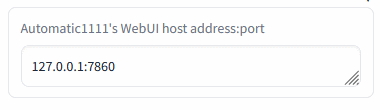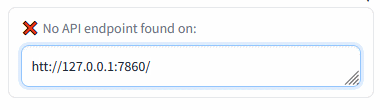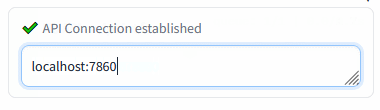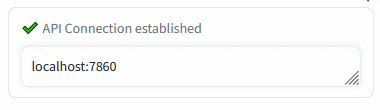
Connection check (insert the Auto1111's address and press Enter):
|
Insert the Automatic1111's WebUI address and press Enter:
|
||||||
|
|
||||||
|
Green mark confirms the ability to communicate with Auto1111's API on this address. Red cross means something's not right (the ext won't work).
|
||||||
|
|
||||||
### Persistents settings
|
### Persistents settings
|
||||||
|
|
||||||
|
|||||||
@ -138,14 +138,19 @@ def get_SD_pictures(description):
|
|||||||
|
|
||||||
visible_result = ""
|
visible_result = ""
|
||||||
for img_str in r['images']:
|
for img_str in r['images']:
|
||||||
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
|
||||||
if params['save_img']:
|
if params['save_img']:
|
||||||
|
img_data = base64.b64decode(img_str)
|
||||||
|
|
||||||
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
|
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
|
||||||
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
||||||
output_file.parent.mkdir(parents=True, exist_ok=True)
|
output_file.parent.mkdir(parents=True, exist_ok=True)
|
||||||
image.save(output_file.as_posix())
|
|
||||||
|
with open(output_file.as_posix(), 'wb') as f:
|
||||||
|
f.write(img_data)
|
||||||
|
|
||||||
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
||||||
else:
|
else:
|
||||||
|
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
||||||
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||||
image.thumbnail((300, 300))
|
image.thumbnail((300, 300))
|
||||||
buffered = io.BytesIO()
|
buffered = io.BytesIO()
|
||||||
|
|||||||
@ -185,10 +185,11 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
|||||||
|
|
||||||
def generate_prompt(data_point: dict[str, str]):
|
def generate_prompt(data_point: dict[str, str]):
|
||||||
for options, data in format_data.items():
|
for options, data in format_data.items():
|
||||||
if set(options.split(',')) == set(x[0] for x in data_point.items() if len(x[1].strip()) > 0):
|
if set(options.split(',')) == set(x[0] for x in data_point.items() if (x[1] != None and len(x[1].strip()) > 0)):
|
||||||
for key, val in data_point.items():
|
for key, val in data_point.items():
|
||||||
data = data.replace(f'%{key}%', val)
|
if val != None:
|
||||||
return data
|
data = data.replace(f'%{key}%', val)
|
||||||
|
return data
|
||||||
raise RuntimeError(f'Data-point "{data_point}" has no keyset match within format "{list(format_data.keys())}"')
|
raise RuntimeError(f'Data-point "{data_point}" has no keyset match within format "{list(format_data.keys())}"')
|
||||||
|
|
||||||
def generate_and_tokenize_prompt(data_point):
|
def generate_and_tokenize_prompt(data_point):
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user